Benutzeranleitung für DBUtils
- Version:
- 3.1.2
- Translations:
English | German
Zusammenfassung
DBUtils ist eine Sammlung von Python-Modulen, mit deren Hilfe man in Python geschriebene Multithread-Anwendungen auf sichere und effiziente Weise an Datenbanken anbinden kann.
DBUtils wurde ursprünglich speziell für Webware for Python als Anwendung und PyGreSQL als PostgreSQL-Datenbankadapter entwickelt, kann aber inzwischen für beliebige Python-Anwendungen und beliebige auf DB-API 2 beruhende Python-Datenbankadapter verwendet werden.
Module
DBUtils ist als Python-Package realisiert worden, das aus zwei verschiedenen Gruppen von Modulen besteht: Einer Gruppe zur Verwendung mit beliebigen DB-API-2-Datenbankadaptern, und einer Gruppe zur Verwendung mit dem klassischen PyGreSQL-Datenbankadapter-Modul.
Allgemeine Variante für beliebige DB-API-2-Adapter |
|
|---|---|
steady_db |
Gehärtete DB-API-2-Datenbankverbindungen |
pooled_db |
Pooling für DB-API-2-Datenbankverbindungen |
persistent_db |
Persistente DB-API-2-Datenbankverbindungen |
simple_pooled_db |
Einfaches Pooling für DB-API 2 |
Variante speziell für den klassischen PyGreSQL-Adapter |
|
|---|---|
steady_pg |
Gehärtete klassische PyGreSQL-Verbindungen |
pooled_pg |
Pooling für klassische PyGreSQL-Verbindungen |
persistent_pg |
Persistente klassische PyGreSQL-Verbindungen |
simple_pooled_pg |
Einfaches Pooling für klassisches PyGreSQL |
Die Abhängigkeiten der Module in der Variante für beliebige DB-API-2-Adapter sind im folgenden Diagramm dargestellt:
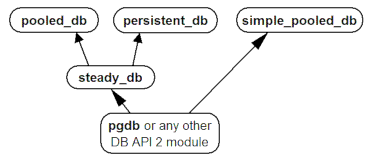
Die Abhängigkeiten der Module in der Variante für den klassischen PyGreSQL-Adapter sehen ähnlich aus:

Download
Die aktuelle Version von DBUtils kann vom Python Package Index heruntergeladen werden:
https://pypi.python.org/pypi/DBUtils
Das Source-Code-Repository befindet sich hier auf GitHub:
https://github.com/WebwareForPython/DBUtils
Installation
Installation
Das Paket kann auf die übliche Weise installiert werden:
python setup.py install
Noch einfacher ist, das Paket in einem Schritt mit pip automatisch herunterzuladen und zu installieren:
pip install DBUtils
Anforderungen
DBUtils unterstützt die Python Versionen 3.7 bis 3.3.
Die Module in der Variante für klassisches PyGreSQL benötigen PyGreSQL Version 4.0 oder höher, während die Module in der allgemeinen Variante für DB-API 2 mit jedem beliebigen Python-Datenbankadapter-Modul zusammenarbeiten, das auf DB-API 2 basiert.
Funktionalität
Dieser Abschnitt verwendet nur die Bezeichnungen der DB-API-2-Variante, aber Entsprechendes gilt auch für die PyGreSQL-Variante.
DBUtils installiert sich als Paket dbutils, das alle hier beschriebenen Module enthält. Jedes dieser Modul enthält im Wesentlichen eine Klasse, die einen analogen Namen trägt und die jeweilige Funktionalität bereitstellt. So enthält z.B. das Modul dbutils.pooled_db die Klasse PooledDB.
SimplePooledDB (simple_pooled_db)
Die Klasse SimplePooledDB in dbutils.simple_pooled_db ist eine sehr elementare Referenz-Implementierung eines Pools von Datenbankverbindungen. Hiermit ist ein Vorratsspeicher an Datenbankverbindungen gemeint, aus dem sich die Python-Anwendung bedienen kann. Diese Implementierung ist weit weniger ausgefeilt als das eigentliche pooled_db-Modul und stellt insbesondere keine Ausfallsicherung zur Verfügung. dbutils.simple_pooled_db ist im Wesentlichen identisch mit dem zu Webware for Python gehörenden Modul MiscUtils.DBPool. Es ist eher zur Verdeutlichung des Konzepts gedacht, als zum Einsatz im produktiven Betrieb.
SteadyDBConnection (steady_db)
Die Klasse SteadyDBConnection im Modul dbutils.steady_db stellt "gehärtete" Datenbankverbindungen bereit, denen gewöhnlichen Verbindungen eines DB-API-2-Datenbankadapters zugrunde liegen. Eine "gehärtete" Verbindung wird bei Zugriff automatisch, ohne dass die Anwendung dies bemerkt, wieder geöffnet, wenn sie geschlossen wurde, die Datenbankverbindung unterbrochen wurde, oder wenn sie öfter als ein optionales Limit genutzt wurde.
Ein typisches Beispiel wo dies benötig wird, ist, wenn die Datenbank neu gestartet wurde, während Ihre Anwendung immer noch läuft und Verbindungen zur Datenbank offen hat, oder wenn Ihre Anwendung auf eine entfernte Datenbank über ein Netzwerk zugreift, das durch eine Firewall geschützt ist, und die Firewall neu gestartet wurde und dabei ihren Verbindungsstatus verloren hat.
Normalerweise benutzen Sie das steady_db-Modul nicht direkt; es wird aber von den beiden nächsten Modulen benötigt, persistent_db und pooled_db.
PersistentDB (persistent_db)
Die Klasse PersistentDB im Modul dbutils.persistent_db stellt gehärtete, thread-affine, persistente Datenbankverbindungen zur Verfügung, unter Benutzung eines beliebigen DB-API-2-Datenbankadapters. Mit "thread-affin" und "persistent" ist hierbei gemeint, dass die einzelnen Datenbankverbindungen den jeweiligen Threads fest zugeordnet bleiben und während der Laufzeit des Threads nicht geschlossen werden.
Das folgende Diagramm zeigt die beteiligten Verbindungsschichten, wenn Sie persistent_db-Datenbankverbindungen einsetzen:
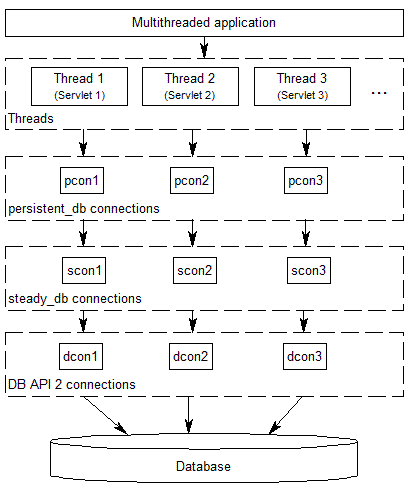
Immer wenn ein Thread eine Datenbankverbindung zum ersten Mal öffnet, wird eine neue Datenbankverbindung geöffnet, die von da an immer wieder für genau diesen Thread verwendet wird. Wenn der Thread die Datenbankverbindung schließt, wird sie trotzdem weiter offen gehalten, damit beim nächsten Mal, wenn der gleiche Thread wieder eine Datenbankverbindung anfordert, diese gleiche bereits geöffnete Datenbankverbindung wieder verwendet werden kann. Die Verbindung wird automatisch geschlossen, wenn der Thread beendet wird.
Kurz gesagt versucht persistent_db Datenbankverbindungen wiederzuverwerten, um die Gesamteffizienz der Datenbankzugriffe Ihrer Multithread-Anwendungen zu steigern, aber es wird dabei sichergestellt, dass verschiedene Threads niemals die gleiche Verbindung benutzen.
Daher arbeitet persistent_db sogar dann problemlos, wenn der zugrunde liegende DB-API-2-Datenbankadapter nicht thread-sicher auf der Verbindungsebene ist, oder wenn parallele Threads Parameter der Datenbank-Sitzung verändern oder Transaktionen mit mehreren SQL-Befehlen durchführen.
PooledDB (pooled_db)
Die Klasse PooledDB im Modul dbutils.pooled_db stellt, unter Benutzung eines beliebigen DB-API-2-Datenbankadapters, einen Pool von gehärteten, thread-sicheren Datenbankverbindungen zur Verfügung, die automatisch, ohne dass die Anwendung dies bemerkt, wiederverwendet werden.
Das folgende Diagramm zeigt die beteiligten Verbindungsschichten, wenn Sie pooled_db-Datenbankverbindungen einsetzen:
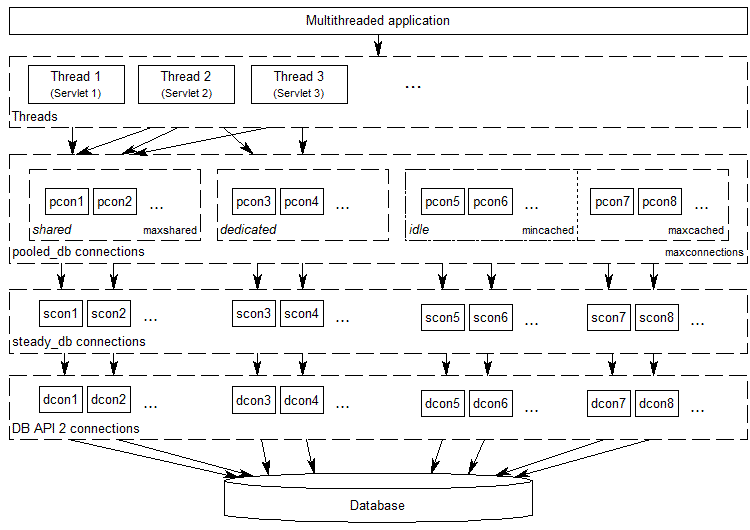
Wie im Diagramm angedeutet, kann pooled_db geöffnete Datenbankverbindungen den verschiedenen Threads beliebig zuteilen. Dies geschieht standardmäßig, wenn Sie den Verbindungspool mit einem positiven Wert für maxshared einrichten und der zugrunde liegende DB-API-2-Datenbankadapter auf der Verbindungsebene thread-sicher ist, aber sie können auch dedizierte Datenbankverbindungen anfordern, die nicht von anderen Threads verwendet werden sollen. Neben dem Pool gemeinsam genutzter Datenbankverbindungen ("shared pool") können Sie auch einen Pool von mindestens mincached und höchstens maxcached inaktiven Verbindungen auf Vorrat einrichten ("idle pool"), aus dem immer dann geschöpft wird, wenn ein Thread eine dedizierte Datenbankverbindung anfordert, oder wenn der Pool gemeinsam genutzter Datenbankverbindungen noch nicht voll ist. Wenn ein Thread eine Datenbankverbindung schließt, die auch von keinem anderen Thread mehr benutzt wird, wird sie an den Vorratsspeicher inaktiver Datenbankverbindungen zurückgegeben, damit sie wiederverwertet werden kann.
Wenn der zugrunde liegende DB-API-Datenbankadapter nicht thread-sicher ist, werden Thread-Locks verwendet, um sicherzustellen, dass die pooled_db-Verbindungen dennoch thread-sicher sind. Sie brauchen sich also hierum keine Sorgen zu machen, aber Sie sollten darauf achten, dedizierte Datenbankverbindungen zu verwenden, sobald Sie Parameter der Datenbanksitzung verändern oder Transaktionen mit mehreren SQL-Befehlen ausführen.
Die Qual der Wahl
Sowohl persistent_db als auch pooled_db dienen dem gleichen Zweck, nämlich die Effizienz des Datenbankzugriffs durch Wiederverwendung von Datenbankverbindungen zu steigern, und dabei gleichzeitig die Stabilität zu gewährleisten, selbst wenn die Datenbankverbindung unterbrochen wird.
Welches der beiden Module sollte also verwendet werden? Nach den obigen Erklärungen ist es klar, dass persistent_db dann sinnvoller ist, wenn Ihre Anwendung eine gleich bleibende Anzahl Threads verwendet, die häufig auf die Datenbank zugreifen. In diesem Fall werden Sie ungefähr die gleiche Anzahl geöffneter Datenbankverbindungen erhalten. Wenn jedoch Ihre Anwendung häufig Threads beendet und neu startet, dann ist pooled_db die bessere Lösung, die auch mehr Möglichkeiten zur Feineinstellung zur Verbesserung der Effizienz erlaubt, insbesondere bei Verwendung eines thread-sicheren DB-API-2-Datenbankadapters.
Da die Schnittstellen beider Module sehr ähnlich sind, können Sie recht einfach von einem Modul zum anderen wechseln und austesten, welches geeigneter ist.
Benutzung
Die Benutzung aller Module ist zwar recht ähnlich, aber es gibt vor allem bei der Initialisierung auch einige Unterschiede, sowohl zwischen den "Pooled"- und den "Persistent"-Varianten, als auch zwischen den DB-API-2- und den PyGreSQL-Varianten.
Wir werden hier nur auf das persistent_db-Modul und das etwas kompliziertere pooled_db-Modul eingehen. Einzelheiten zu den anderen Modulen finden Sie in deren Docstrings. Unter Verwendung der Python-Interpreter-Konsole können Sie sich die Dokumentation des pooled_db-Moduls wie folgt anzeigen lassen (dies funktioniert entsprechend auch mit den anderen Modulen):
help(pooled_db)
PersistentDB (persistent_db)
Wenn Sie das persistent_db-Modul einsetzen möchten, müssen Sie zuerst einen Generator für die von Ihnen gewünschte Art von Datenbankverbindungen einrichten, indem Sie eine Instanz der Klasse persistent_db erzeugen, wobei Sie folgende Parameter angeben müssen:
creator: entweder eine Funktion, die neue DB-API-2-Verbindungen erzeugt, oder ein DB-API-2-Datenbankadapter-Modul
maxusage: Obergrenze dafür, wie oft eine einzelne Verbindung wiederverwendet werden darf (der Standardwert 0 oder None bedeutet unbegrenzte Wiederverwendung)
Sobald diese Obergrenze erreicht wird, wird die Verbindung zurückgesetzt.
setsession: eine optionale Liste von SQL-Befehlen zur Initialisierung der Datenbanksitzung, z.B. ["set datestyle to german", ...]
failures: eine optionale Exception-Klasse oder ein Tupel von Exceptions, bei denen die Ausfallsicherung zum Tragen kommen soll, falls die Vorgabe (OperationalError, InterfaceError, InternalError) für das verwendete Datenbankadapter-Modul nicht geeignet sein sollte
ping: mit diesem Parameter kann eingestellt werden, wann Verbindungen mit der ping()-Methode geprüft werden, falls eine solche vorhanden ist (0 = None = nie, 1 = Standardwert = immer wenn neu angefragt, 2 = vor Erzeugen eines Cursors, 4 = vor dem Ausführen von Abfragen, 7 = immer, und alle Bitkombinationen dieser Werte)
closeable: wenn dies auf True gesetzt wird, dann wird das Schließen von Verbindungen erlaubt, normalerweise wird es jedoch ignoriert
threadlocal: eine optionale Klasse zur Speicherung thread-lokaler Daten, die anstelle unserer Python-Implementierung benutzt wird (threading.local ist schneller, kann aber nicht in allen Fällen verwendet werden)
Die als creator angegebene Funktion oder die Funktion connect des DB-API-2-Datenbankadapter-Moduls erhalten alle weiteren Parameter, wie host, database, user, password usw. Sie können einige oder alle dieser Parameter in Ihrer eigenen creator-Funktion setzen, was ausgefeilte Mechanismen zur Ausfallsicherung und Lastverteilung ermöglicht.
Wenn Sie beispielsweise pgdb als DB-API-2-Datenbankadapter verwenden, und möchten, dass jede Verbindung Ihrer lokalen Datenbank meinedb 1000 mal wiederverwendet werden soll, sieht die Initialisierung so aus:
import pgdb # importiere das verwendete DB-API-2-Modul from dbutils.persistent_db import PersistentDB persist = PersistentDB(pgdb, 1000, database='meinedb')
Nachdem Sie den Generator mit diesen Parametern eingerichtet haben, können Sie derartige Datenbankverbindungen von da an wie folgt anfordern:
db = persist.connection()
Sie können diese Verbindungen verwenden, als wären sie gewöhnliche DB-API-2-Datenbankverbindungen. Genauer genommen erhalten Sie die "gehärtete" steady_db-Version der zugrunde liegenden DB-API-2-Verbindung.
Wenn Sie eine solche persistente Verbindung mit db.close() schließen, wird dies stillschweigend ignoriert, denn sie würde beim nächsten Zugriff sowieso wieder geöffnet, und das wäre nicht im Sinne persistenter Verbindungen. Stattdessen wird die Verbindung automatisch dann geschlossen, wenn der Thread endet. Sie können dieses Verhalten ändern, indem Sie den Parameter namens closeable setzen.
Das Holen einer Verbindung kann etwas beschleunigt werden, indem man den Parameter threadlocal auf threading.local setzt; dies könnte aber in einigen Umgebungen nicht funktionieren (es ist zum Beispiel bekannt, dass mod_wsgi hier Probleme bereitet, da es Daten, die mit threading.local gespeichert wurden, zwischen Requests löscht).
PooledDB (pooled_db)
Wenn Sie das pooled_db-Modul einsetzen möchten, müssen Sie zuerst einen Pool für die von Ihnen gewünschte Art von Datenbankverbindungen einrichten, indem Sie eine Instanz der Klasse pooled_db erzeugen, wobei Sie folgende Parameter angeben müssen:
creator: entweder eine Funktion, die neue DB-API-2-Verbindungen erzeugt, oder ein DB-API-2-Datenbankadapter-Modul
mincached : die anfängliche Anzahl inaktiver Verbindungen, die auf Vorrat gehalten werden sollen (der Standardwert 0 bedeutet, dass beim Start keine Verbindungen geöffnet werden)
maxcached: Obergrenze für die Anzahl inaktiver Verbindungen, die auf Vorrat gehalten werden sollen (der Standardwert 0 oder None bedeutet unbegrenzte Größe des Vorratsspeichers)
maxshared: Obergrenze für die Anzahl gemeinsam genutzer Verbindungen (der Standardwert 0 oder None bedeutet, dass alle Verbindungen dediziert sind)
Wenn diese Obergrenze erreicht wird, werden Verbindungen wiederverwendet, wenn diese als wiederverwendbar angefordert werden.
maxconnections: Obergrenze für die Anzahl an Datenbankverbindungen, die insgesamt überhaupt erlaubt werden sollen (der Standardwert 0 oder None bedeutet unbegrenzte Anzahl von Datenbankverbindungen)
blocking: bestimmt das Verhalten bei Überschreitung dieser Obergrenze
Wenn dies auf True gesetzt wird, dann wird so lange gewartet, bis die Anzahl an Datenbankverbindungen wieder abnimmt, normalerweise wird jedoch sofort eine Fehlermeldung ausgegeben.
maxusage: Obergrenze dafür, wie oft eine einzelne Verbindung wiederverwendet werden darf (der Standardwert 0 oder None bedeutet unbegrenzte Wiederverwendung)
Sobald diese Obergrenze erreicht wird, wird die Verbindung automatisch zurückgesetzt (geschlossen und wieder neu geöffnet).
setsession: eine optionale Liste von SQL-Befehlen zur Initialisierung der Datenbanksitzung, z.B. ["set datestyle to german", ...]
reset: wie Verbindungen zurückgesetzt werden sollen, bevor sie wieder in den Verbindungspool zurückgegeben werden (False oder None um mit begin() gestartete Transaktionen zurückzurollen, der Standardwert True rollt sicherheitshalber mögliche Transaktionen immer zurück)
failures: eine optionale Exception-Klasse oder ein Tupel von Exceptions, bei denen die Ausfallsicherung zum Tragen kommen soll, falls die Vorgabe (OperationalError, InterfaceError, InternalError) für das verwendete Datenbankadapter-Modul nicht geeignet sein sollte
ping: mit diesem Parameter kann eingestellt werden, wann Verbindungen mit der ping()-Methode geprüft werden, falls eine solche vorhanden ist (0 = None = nie, 1 = Standardwert = immer wenn neu angefragt, 2 = vor Erzeugen eines Cursors, 4 = vor dem Ausführen von Abfragen, 7 = immer, und alle Bitkombinationen dieser Werte)
Die als creator angegebene Funktion oder die Funktion connect des DB-API-2-Datenbankadapter-Moduls erhalten alle weiteren Parameter, wie host, database, user, password usw. Sie können einige oder alle dieser Parameter in Ihrer eigenen creator-Funktion setzen, was ausgefeilte Mechanismen zur Ausfallsicherung und Lastverteilung ermöglicht.
Wenn Sie beispielsweise pgdb als DB-API-2-Datenbankadapter benutzen, und einen Pool von mindestens fünf Datenbankverbindungen zu Ihrer Datenbank meinedb verwenden möchten, dann sieht die Initialisierung so aus:
import pgdb # importiere das verwendete DB-API-2-Modul from dbutils.pooled_db import PooledDB pool = PooledDB(pgdb, 5, database='meinedb')
Nachdem Sie den Pool für Datenbankverbindungen so eingerichtet haben, können Sie Verbindungen daraus wie folgt anfordern:
db = pool.connection()
Sie können diese Verbindungen verwenden, als wären sie gewöhnliche DB-API-2-Datenbankverbindungen. Genauer genommen erhalten Sie die "gehärtete" steady_db-Version der zugrunde liegenden DB-API-2-Verbindung.
Bitte beachten Sie, dass die Verbindung von anderen Threads mitgenutzt werden kann, wenn Sie den Parameter maxshared auf einen Wert größer als Null gesetzt haben, und der zugrunde liegende DB-API-2-Datenbankadapter dies erlaubt. Eine dedizierte Datenbankverbindung, die garantiert nicht von anderen Threads mitgenutzt wird, fordern Sie wie folgt an:
db = pool.connection(shareable=False)
Stattdessen können Sie eine dedizierte Verbindung auch wie folgt erhalten:
db = pool.dedicated_connection()
Wenn Sie die Datenbankverbindung nicht mehr benötigen, sollten Sie diese sofort wieder mit db.close() an den Pool zurückgeben. Sie können auf die gleiche Weise eine neue Verbindung erhalten.
Warnung: In einer Multithread-Umgebung benutzen Sie niemals:
pool.connection().cursor().execute(...)
Dies würde die Datenbankverbindung zu früh zur Wiederverwendung zurückgeben, was fatale Folgen haben könnte, wenn die Verbindungen nicht thread-sicher sind. Stellen Sie sicher, dass die Verbindungsobjekte so lange vorhanden sind, wie sie gebraucht werden, etwa so:
db = pool.connection() cur = db.cursor() cur.execute(...) res = cur.fetchone() cur.close() # oder del cur db.close() # oder del db
Sie können dies auch durch Verwendung von Kontext-Managern vereinfachen:
with pool.connection() as db:
with db.cursor() as cur:
cur.execute(...)
res = cur.fetchone()
Besonderheiten bei der Benutzung
Manchmal möchte man Datenbankverbindung besonders vorbereiten, bevor sie von DBUtils verwendet werden, und dies ist nicht immer durch Verwendung der passenden Parameter möglich. Zum Beispiel kann es pyodb erfordern, dass man die Methode setencoding() der Datenbankverbindung aufruft. Sie können dies erreichen, indem Sie eine modifizierte Version der Funktion connect() verwenden und diese als creator (dem ersten Argument) an PersistentDB oder PooledDB übergeben, etwa so:
from pyodbc import connect
from dbutils.pooled_db import PooledDB
def creator():
con = connect(...)
con.setdecoding(...)
return con
creator.dbapi = pyodbc
db_pool = PooledDB(creator, mincached=5)
Anmerkungen
Wenn Sie einen der bekannten "Object-Relational Mapper" SQLObject oder SQLAlchemy verwenden, dann benötigen Sie DBUtils nicht, denn diese haben ihre eigenen Mechanismen zum Pooling von Datenbankverbindungen eingebaut. Tatsächlich hat SQLObject 2 (SQL-API) das Pooling in eine separate Schicht ausgelagert, in der Code von DBUtils verwendet wird.
Wenn Sie eine Lösung verwenden wie den Apache-Webserver mit mod_python oder mod_wsgi, dann sollten Sie bedenken, dass Ihr Python-Code normalerweise im Kontext der Kindprozesse des Webservers läuft. Wenn Sie also das pooled_db-Modul einsetzen, und mehrere dieser Kindprozesse laufen, dann werden Sie ebenso viele Pools mit Datenbankverbindungen erhalten. Wenn diese Prozesse viele Threads laufen lassen, dann mag dies eine sinnvoller Ansatz sein, wenn aber diese Prozesse nicht mehr als einen Worker-Thread starten, wie im Fall des Multi-Processing Moduls "prefork" für den Apache-Webserver, dann sollten Sie auf eine Middleware für das Connection-Pooling zurückgreifen, die Multi-Processing unterstützt, wie zum Beispiel pgpool oder pgbouncer für die PostgreSQL-Datenbank.
Zukunft
Einige Ideen für zukünftige Verbesserungen:
Alternativ zur Obergrenze in der Anzahl der Nutzung einer Datenbankverbindung könnte eine maximale Lebensdauer für die Verbindung implementiert werden.
Es könnten Module monitor_db und monitor_pg hinzugefügt werden, die in einem separaten Thread ständig den "idle pool" und eventuell auch den "shared pool" bzw. die persistenten Verbindungen überwachen. Wenn eine unterbrochene Datenbankverbindung entdeckt wird, wird diese automatisch durch den Monitor-Thread wiederhergestellt. Dies ist in einem Szenario sinnvoll, bei dem die Datenbank einer Website jede Nacht neu gestartet wird. Ohne den Monitor-Thread würden die Benutzer morgens eine kleine Verzögerung bemerken, weil erst dann die unterbrochenen Datenbankverbindungen entdeckt würden und sich der Pool langsam wieder neu aufbaut. Mit dem Monitor-Thread würde dies schon während der Nacht passieren, kurz nach der Unterbrechung. Der Monitor-Thread könnte auch so konfiguriert werden, dass er überhaupt täglich den Verbindungspool erneuert, kurz bevor die Benutzer erscheinen.
Optional sollten Benutzung, schlechte Verbindungen und Überschreitung von Obergrenzen in Logs gespeichert werden können.
Fehlermeldungen und Feedback
Fehlermeldungen, Patches und Feedback können Sie als Issues oder Pull Requests auf der GitHub-Projektseite von DBUtils übermitteln.
Links
Einige Links zu verwandter und alternativer Software:
Webware for Python Framework
Python DB-API 2
PostgreSQL Datenbank
PyGreSQL Python-Adapter for PostgreSQL
pgpool Middleware für Connection-Pooling mit PostgreSQL
pgbouncer Middleware für Connection-Pooling mit PostgreSQL
SQLObject Objekt-relationaler Mapper
SQLAlchemy Objekt-relationaler Mapper
Autoren
- Autor:
- Beiträge:
DBUtils benutzt Code, Anmerkungen und Vorschläge von Ian Bicking, Chuck Esterbrook (Webware for Python), Dan Green (DBTools), Jay Love, Michael Palmer, Tom Schwaller, Geoffrey Talvola, Warren Smith (DbConnectionPool), Ezio Vernacotola, Jehiah Czebotar, Matthew Harriger, Gregory Piñero und Josef van Eenbergen.
Copyright und Lizenz
Copyright © 2005-2025 Christoph Zwerschke. Alle Rechte vorbehalten.
DBUtils ist freie und quelloffene Software, lizenziert unter der MIT-Lizenz.